
Alexa, Siri, and Cortana—many of us have encountered this trio of virtual assistants in our day-to-day tasks. They can help in turning on the lights of our home, find information on the internet, and even start a video conference. What many don’t know is that these technologies are dependent on natural language processing.
What is Automatic Speech Recognition (ASR)?
These virtual assistants are applications of automatic speech recognition (ASR). Also known as computer speech recognition, ASR uses artificial intelligence and machine learning algorithms to analyze and convert human speech to text.
Speech Collection to Train ASR Models
To ensure the maximum effectiveness of your ASR models, it is important to collect substantial speech & audio datasets. The goal of speech collection is to collect enough sample recordings to feed and train ASR models.
These speech datasets are used for future comparison against the speech of unknown speakers using unspecified speaker recognition methods. For ASR systems to work as intended, speech collection must be conducted for all target demographics, languages, dialects, and accents.
Artificial intelligence can only be as intelligent as the data it’s given. It is important to collect substantial speech or audio datasets to train an ASR model with maximum effectiveness. We’ve outlined the steps in speech data collection to effectively train your machine learning learning model:
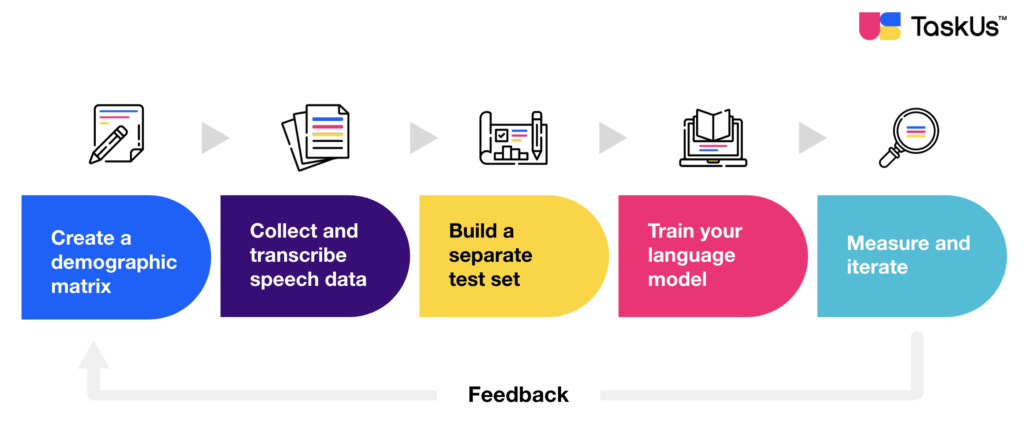
- Create a demographic matrix. Consider the following information: location, language, genders, ages, accents. Note also the variety of environments (a busy street, an open office, or a waiting room) and their use of devices (mobile phone, desktop, or headset).
- Collect and transcribe speech data. Gather audio and speech samples from real humans to train your model. In this step, you will need human transcriptionists to take note of long and short utterances and key details following your demographic matrix. Humans remain essential in building properly labelled speech and audio datasets to provide a baseline for further application and development.
- Build a separate test set. Now that you have your transcribed text, pair it with the corresponding audio data and segment them to include one statement each. Take the segmented pairs and extract a random 20% of the data to form a set for testing.
- Train your language model. Generate additional variations of text that was not initially recorded. For example, in cancelling orders, you only recorded the statement “I want to cancel my order.” In this step, you can add “Can I cancel my subscription?” and “I want to unsubscribe.” You can also provide relevant expressions and jargon.
- Measure and iterate. Evaluate output of your ASR to benchmark performance. Take the trained model and measure how well it predicts the test set. Engage your machine learning model in a feedback loop to fix any gaps and yield the desired output.
Related: Human-in-the-Loop Machine Learning: How Humans Keep AI Models in Check
Applications of Speech Recognition
Other than virtual assistants, speech recognition systems are also being used across various industries:
Travel and Transportation
According to Automotive World, 90% of new vehicles sold by 2028 will be voice-assisted. Applications like Apple CarPlay or Google Android Auto integrate voice data to activate navigation systems, send a message, or switch music playlists in a car’s entertainment system.
BMW partnered with Microsoft-acquired Nuance to power the BMW Intelligent Personal Assistant first available in the BMW 3 Series. The AI-powered digital companion enables drivers to operate their car and access information, such as the entire car manual, using only the driver’s voice.
Food
Fast food giants McDonald’s and Wendy’s are leveling up their customer experience with the use of automatic speech recognition. An AI platform transcribes the voice data and gives them to the cooks for preparation. The integration of speech recognition systems result in fast and frictionless interactions and lower labor cost.
Media and Entertainment
YouTube’s audio AI-based features expands to include live auto captions. This means that creators can now do live streams with captions automatically seen at the bottom of the screen. This ASR feature will soon be available in more languages to make streams more inclusive and accessible.
Telecommunication
Many telecom service providers such as Vodafone use ASR technology in telephone relay services and customer care centers to address customer queries or forward calls to concerned departments for a quick solution.
Audio and Speech Data Collection Services with Us
To understand natural language, algorithms need to be trained with large sets of written or spoken data that has been annotated based on parts of speech, meaning, and sentiment. At TaskUs, here’s what we bring to the conversation: over a decade of experience in collecting and enhancing text and speech data for machine learning.
We have an average score of 98% QA score in all data-related operations. We customize the build of our teams empowering them with best-in-class tooling to support a wide range of projects and workflows. We provide enterprise-level security options for sensitive data or compliance needs. With our global footprint, we can efficiently execute large-scale global programs catered specifically to your company’s data collection, annotation, and evaluation needs.
Our services for audio and speech data collection include:
- Audio transcription
- Data evaluation
- Multilingual data collection
- Sentiment analysis
