
Deep learning models rely on extensive image or video data to be successful. However, even a single image contains a wealth of information that models must accurately locate and recognize before making accurate predictions. This is where image segmentation techniques, specifically semantic image segmentation, play a crucial role.
In this article, we’ll discuss what is segmentation in image processing, what is semantic segmentation and its importance, and the various nuanced applications of semantic segmentation.
Understanding Semantic Segmentation: The Basics
Businesses are increasingly investing in computer vision and machine learning models to garner a competitive edge in their market. But to ensure their machines will even work correctly, let alone give them an advantage over the competition, engineers must use millions of images and videos to create high-quality training datasets for their models. These files must then be broken down and categorized on a per-pixel level through a process called semantic image segmentation.
What are Image Segmentation in Machine Learning and Semantic Image Segmentation?
Image segmentation is a computer vision technique that divides an image into separate regions or segments based on various visual properties like color and texture to analyze further and understand an image’s content. This way, machine learning solutions and models can isolate, detect, or recognize objects in an image.
On the other hand, semantic image segmentation is a more advanced image segmentation technique of assigning semantic labels to each pixel in the image, providing a more granular level of detail. This level of granularity enhances the machine’s learning process and enables it to understand more complex elements, such as spatial relationships and boundaries between different objects in an image. For example, to train autonomous driving vehicles, parts of images are classified into vehicles, pedestrians, road dividers, and traffic signs.

Every pixel in the image is classified in a category or label.
Semantic image segmentation facilitates precise object localization and boundary delineation by providing pixel-level annotations, empowering machine learning models to make more accurate predictions and better understand visual data.
In the case of autonomous driving vehicles, computer vision semantic segmentation helps machines distinguish a pedestrian from a traffic sign, a road from a building, and a tree from a house to ensure road safety. This technique is crucial in creating effective computer vision models that rely heavily on training and testing data in machine learning.
The Semantic Segmentation Process
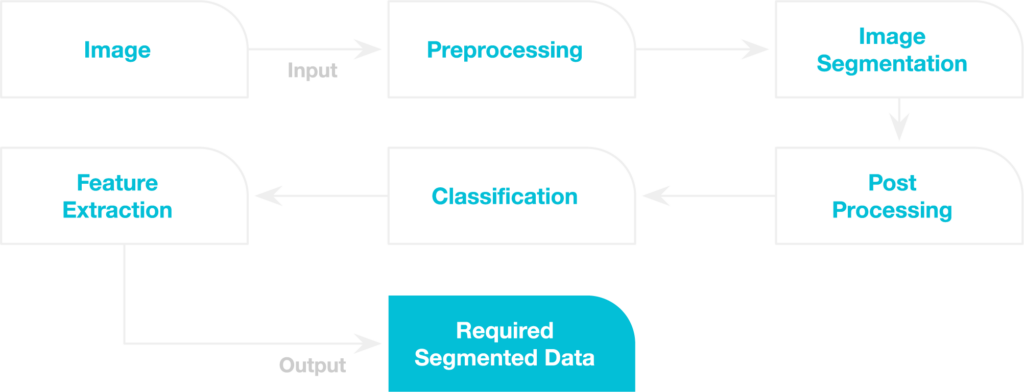
The whole process involves an image segmentation convolutional neural network (CNN), a specific type of deep learning architecture designed for image segmentation. From preparation to output, here’s a quick overview of how semantic segmentation models work:
- Pre-processing Images
Before the segmentation process begins, images are pre-processed to enhance their suitability for analysis. This step involves resizing, noise reduction, and color normalization to ensure consistent and optimal input for the model.
- Feature Extraction
Next, the pre-processed images are passed through neural networks that extract relevant features essential for the specific use case. These deep-learning models analyze the images and identify distinctive patterns, shapes, and textures that differentiate various objects or regions.
- Classification
Once the relevant features are extracted, the classification phase takes place. The extracted features classify each pixel, assigning it a specific label or class. This process allows the machine learning model to differentiate between different objects.
- Output Visualization
To visualize semantic segmentation results, an overlay of a segmentation mask is added to the image, highlighting the specific class or object of interest. This helps distinguish the identified objects from the rest of the image.
Applications of Semantic Segmentation
Semantic segmentation services empower various industries and businesses to precisely analyze and interpret visual data. Here are some key areas where semantic image segmentation is widely used.
- Autonomous Driving
Semantic segmentation machine learning has a tremendous impact on autonomous technology’s functionality, security, and safety. It enables real-time identification and categorization of pedestrians, vehicles, road boundaries, and other objects. Providing an autonomous model with a precise understanding of its environment ensures safer and more reliable experiences and minimizes the risk of mistakes or injury.
- Medical Imaging
In medical imaging, semantic segmentation helps medical experts recognize and analyze anomalies within images, such as tumors or organ abnormalities. Accurate segmentation also plays a crucial role in diagnosis, treatment planning, and monitoring the progress of diseases.
- Robotic Vision
The pixel-level accuracy semantic segmentation in deep learning provides can significantly enhance robotic vision tasks. With precise segmentation, these robots can effectively perform visually complex tasks such as object manipulation, navigation, and obstacle avoidance.
- Agriculture
Computer vision semantic segmentation aids in crop health assessment and disease detection. Through it, farmers and agronomists can identify specific areas of concern, evaluate individual plant health, and take targeted actions to optimize crop yield and minimize losses.
- Fashion Industry / Virtual Try-On
Virtual try-ons are made possible using computer vision semantic segmentation. With an accurately trained model, users can experience trying on clothing items or even makeup products to help them visualize how these would look on them before making a purchase.
Outsource Semantic Segmentation Services with TaskUs
For years, TaskUs has demonstrated its semantic segmentation expertise in supporting image and video annotation for autonomous driving companies.
One of our clients, a Globally Leading Autonomous Vehicle (AV) Company, partnered with Us to support them in exponentially scaling, refining, and enhancing their AI training through high-precision data image processing solutions.
The project started with 100 FTEs and rapidly grew to over 1,800 FTEs:
- We trained the right teams with contextual data nuances to match in-house working knowledge.
- We trained ‘Super Experts’ who maintained 100% scores across all quality metrics.
- Developed a quality framework from the ground up that we incorporated into the workflow of every dataset.
- Established a weekly headcount forecast with the client to determine optimal staffing and scheduling.
Our results?
- 98% Accuracy Score vs. the original target of 90%
- 115% goal vs. the 90% target
- 24 Tasks Per Day/Teammate vs. the original target of 20
With Us, our client’s autonomous vehicles were able to map the roads faster as we doubled their overall production rate with our proactive approach to robust quality management.
Dubbed by the Everest Group as the World’s Fastest Growing Business Process (Outsourcing) Service Provider in 2022 and with glowing reviews in Gartner Peer Insights, TaskUs is a proven partner in image annotation outsourcing and web search evaluation services.
From deploying teams of image annotation experts to ensuring data security and maintaining meticulous quality checks–we’ve got every step covered to ensure your models’ and investment’s success.
