
Machine learning is becoming ubiquitous. While these applications require tremendous volumes of AI training data, highly automated revolutionary technologies still require humans behind the scenes to manually label data before they can effectively train AI models.
Humans label thousands of data used to train AI systems. For example, to teach a computer how to identify cats, you would need someone to label the images as either “cat” or “no cat.” This process is called data labeling and companies do it for many types of datasets. And because of the sheer amount of data required, crowdsourcing data labeling is an essential process in the development of machine learning algorithms.
What is Crowdsourced Data Labeling?
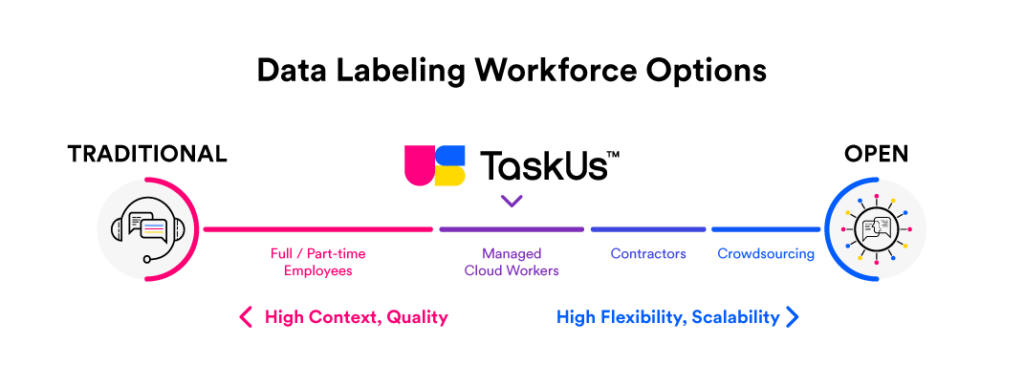
Crowdsourced data labeling is breaking down training data labeling projects into smaller tasks to be distributed among a large crowd of contractors or temporary employees.
Through crowdsourced data labeling, teams can collect large amounts of valuable and diverse data samples at a cost typically lower than that of traditional data collection methods.
The most common use case for crowdsourcing data labeling is to collect and label images, videos, and audio clips. This is useful in computer vision, speech recognition, and other machine learning tasks.
Benefits of Crowdsourced Data Labeling
Crowdsourcing data labeling has been around for a while now and it’s become a popular solution for companies that need help with their data and information management. With it, data labeling services can be done at a lower cost and with more accuracy. It also allows for more diverse perspectives on the data, which can lead to better insights.
Businesses prefer to crowdsource data labeling over carrying out the same projects in-house because of the following benefits:
- Eliminates the need to hire thousands of temporary employees
While many heads are better than one, there are certain setbacks with hiring temps. For instance, permanent employees have to work with different workers every cycle, thus making it hard to connect with their peers. Another disadvantage is the security issues that the company may face if they cycle through temps every quarter.
- Reduces workload for internal data scientists
Data scientists, analysts, and internal teams can focus more on their workload if the company crowdsources the bulk of data labeling. This ensures that adjusted processes are based on headcount and that the quality of the output is within industry standards.
- Lowers operational costs
It’s easier and more affordable to find a trusted crowdsourcing partner than to hire temporary employees. For instance, there is no need for additional investment in annotation tools as an experienced crowdsourcing partner would already have them and have mastered their use.
How to Pick a Crowdsourcing Partner
There are several factors that you should consider when picking a crowdsourced data labeling partner. But choosing the correct crowdsource data labeling partner can be difficult if you don’t know what to look for.
- Understand your requirements
Before you embark on crowdsourcing data entirely, determine first if your requirements are possible. Take a look and understand your data; try labeling some yourself to properly design the task you want to crowdsource.
- Request proof of concept
Evaluate vendors by launching your task to a few of their people. This will give you an idea of the vendor’s capabilities (workflow, speed, quality, etc.). Get your crowdsource job done more efficiently by trying out various data labeling methods that fit your specific needs, including reinforced, supervised, and unsupervised learning.
- Training with feedback
Give incremental feedback to the crowdsourcing company and to annotators to fine-tune the project design. You must walk the fine line between providing adequate information to your partner firm while giving constructive feedback within reasonable bounds.
- Scale
Work with your vendor to scale up the project once you’re happy with your setup. Crowdsourcing data labeling requires certain planning, organization, and follow-through. If you don’t have the resources and know-how to follow through on your crowdsourcing data labeling, it may be difficult for you to get an edge over your competition.
Data Labeling Outsourcing at TaskUs
TaskUs is an AI-powered provider of data labeling solutions. We help businesses with all their data labeling needs, including data management, processing, text analysis, and machine learning on unstructured content. Our enterprise-level solution helps you manage and process your entire dataset across all platforms with high precision, accuracy, and completeness in a cost-effective manner.
Our data labeling capabilities include:
- Image & video data for computer vision
- Text & speech data for natural language processing (NLP)
- Data collection, annotation, and validation for content relevance
Learn more about our Ridiculously Good AI services today.
