
Constant changes in trends, user patterns, and other factors can cause your data to be irrelevant, affecting your artificial intelligence (AI) and machine learning (ML) models. Traditional machine learning models assume that the input data will remain the same as the initial training data. However, there is a constant need for the human eye and judgment to follow through with these changes and integrate data on top of the whole machine learning process. For machine-learning workflows to remain up-to-date, continuous machine learning (CML) must be integrated.
What is Continuous Machine Learning?
Continuous machine learning (CML) refers to an AI/ML model’s ability to learn continuously from a stream of data. It is an open-source machine learning library for Continuous Integration (CI) and Continuous Delivery (CD). CI is the process of automating the integration of code changes from a substantial number of contributors into a single software project. CD, on the other hand, creates applications based on code, data, and models through a cross-functional team to progress into small chunks that can be replicated and dependably deployable at any time.
CML uses a set of tools and methods to constantly update data for ML workflows to advance autonomously, resulting in increased accuracy and efficiency in AI and ML operations. Think of it like raising children—teach them the basics and provide constant education and guidance as they grow up, so that they can learn and make important decisions.
Constant training is a must
When the data properties of an ML model change, it is important to retrain the model to avoid concept drift. Concept drift refers to the evolution between input and output variables over time. CML optimizes the machine learning model’s knowledge, performance, accuracy, and capability to become auto-adaptive to the present.
An example of CML is Netflix’s recommender system, where it suggests the next show right at the end of the last episode. This model needs to be trained periodically to keep up with new releases and changing preferences of the viewers.
CML is also being used in social media. Platforms like Facebook, Instagram, and Twitter have developed analytics tools that provide insights into post-performance, audience demographics, and active time, while suggesting trends to users’ feeds. The same goes for TikTok. It has a well-established infrastructure and its recommendation systems can learn about users’ tastes in real time, which makes every feed personalized and highly addictive.
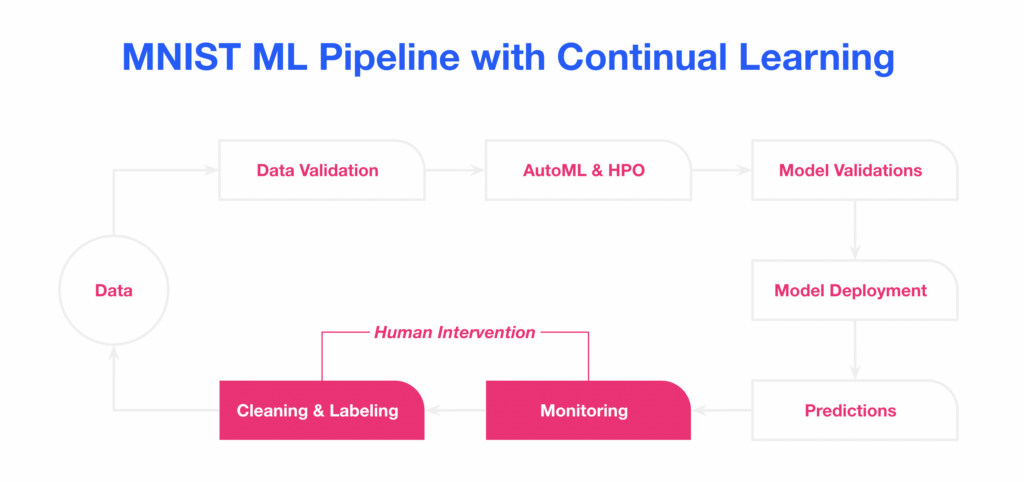
What are the benefits of Continuous Machine Learning?
With a constant flow of data, CML helps machine learning systems and AI models to become adaptable, scalable, and more intelligent.
Scale machine learning initiatives rapidly
In 2017, the world was producing a rate of 16 ZB of data per year. By 2025, IDC reports that production of data will reach 160 ZB. By that time, only 3% to 12% of the data can be stored. To avoid data getting lost, it’s important that ML models process them quickly and efficiently. This is why companies should use CML models to be able to quickly filter and process a lot of data to cut down on storage and maintenance costs.
Furthermore, CML makes multimodal-multitask learning possible. Like humans, we process tons of information at the same time and solve problems through the new information acquired. With CML, alternative asynchronous training of tasks is possible. Hundreds of data can be trained simultaneously, training models at scale to provide better and more accurate output.
Saves re-training time and makes models auto-adaptive
Continuous machine learning from data flows is really important to refine prediction models and ultimately to improve products. This can be seen in Recommendation and Anomaly-detection models that learn from the data received over time and refine their prediction mechanisms.
Automatically diagnose and evaluate AI models against new data
With CML, the machine optimizes its algorithm and makes better predictions and decisions on its own. This is crucial when AI and ML is used in real-world production environments. A constant feedback loop of human judgment is necessary so that the AI model can always be fine-tuned to ensure precise performance, improve confidence, and prevent bias as it deploys into the system.
Related: Human-in-the-Loop Machine Learning: How Humans Keep AI Models in Check
What are the main challenges faced in the CML process?
Gathering the necessary data
It can be very challenging to collect high-quality, precise, and actual data to train an AI model. Public datasets are often not well-curated and not suitable for training models in many applied machine learning applications like continuous machine learning. Data can be either collected in-house or purchased from a third party.
Maintaining the ML models
Machine learning models trained with old data give faulty predictions. To ensure that the model is able to capture evolving and emerging patterns, it needs to be retrained with the most recent and relevant data. This became strongly evident at the onset of the pandemic.
According to Harvard Business Review, the pandemic impacted consumer behavior and caused an information gap in the AI and ML systems. The data collected before the crisis failed to execute accurate prediction patterns, resulting in an increase in demand for new data.
To ensure that your model is able to capture evolving and emerging patterns, it needs to be retrained with the most recent and accurate data. The long-term success of your machine learning model can be achieved with the right infrastructure and regularly updated processes.
Monitoring the CML process
Another challenge in the automated deployment of data is establishing a real-time workflow to monitor the machine learning pipeline. It is essential that you have a mechanism in place to alert you if you experience problems such as getting malicious or corrupted data. Aside from this, you also have to monitor the input data for anomalies and concept drifts.
Continuous Machine Learning with Us
Our AI expertise lies in collecting, annotating, and evaluating data to create cutting-edge AI solutions such as continuous machine learning.
One of our clients, a US-based interactive retail technology developer, partnered with Us to establish a flexible workforce infrastructure, reliable support in creating training materials on real-time image annotation and tagging, and an improved quality assurance system.
- Over 180 Teammates
- 18 million images processed monthly
- and <4 seconds average handling time
Our solutions?
- Efficient workforce management system
- Comprehensive quality infrastructure
- Enhanced agent training for maximum productivity
Along with better ML models, our client was able to specify the transactions they needed from Us, which also helped them better manage their costs.
TaskUs stands out in a fast-paced, tech-dominated industry through its people-first principles and commitment to providing excellent tech services. With more than a decade of experience, growing to over 40,000 employees and 23 sites in 10 countries, and more than 100 global clients, we are highly capable of providing you the best-in-class AI and ML solutions.
