
What is human-in-the-loop machine learning?
Human-in-the-loop machine learning (HITL) simply means this: keeping humans in the loop in the development of machine learning models. It integrates human labelled data into the machine learning model and goes through a feedback cycle to teach models to yield the desired output.
From a retail customer’s perspective, the seamless experience of contactless technology is a dream. Amazon has made it possible with its cashierless Just Walk Out1 technology and smart carts strategy. Behind the scenes is where the “magic” happens. Every item you pick up and put into your cart is labeled. This also triggers inventory management if an item is running low on the shelves. That’s HITL at work. The use of artificial intelligence (AI) has its flaws, particularly in shoplifting detection2, therefore requiring human expertise and guidance.
The goal of HITL is to build smarter machine learning systems to increase work productivity and efficiency.
The goal of HITL is to build smarter machine learning systems. Enhanced by human labelled data, these systems increase work productivity and efficiency. In 2020, Google Health’s medical AI system, DeepMind, for example, detected more than 2,600 breast cancer cases3 than a radiologist would have. However, rather than depending on AI entirely, machine learning systems still perform best when complemented with human intellect. Of how much humans are involved in machine learning4, developers adopt a variation of the Pareto principle—80% computer-driven AI, 19% human input, and 1% randomness.
Three Stages of Human-in-the-Loop Machine Learning
Human-in-the-loop machine learning includes three main stages: training, tuning and testing. Let’s see below how these stages are applied in the machine learning lifecycle:

Training. Oftentimes, data can be incomplete or messy. Humans add labels to raw data to provide meaningful context so that machine learning models can learn to produce desired results, identify patterns, and make correct decisions. Data labeling is a crucial step in building AI models as properly labeled datasets would provide a baseline for further application and development.
Tuning. In this stage, humans check the data for overfitting5. While data labeling establishes the foundation for an accurate output, overfitting happens when the model trains the data too well. When the model memorizes the training dataset, it can make a generalization, thus making it unable to perform against new data. It’s allowing a margin of error to allow unpredictability in real-life scenarios.
It is also in the tuning stage when humans teach the model about edge cases or unexpected scenarios. For example, facial recognition6 enables convenience but is susceptible to gender and ethnicity bias when datasets are misrepresented.
Testing. Lastly, humans evaluate if the algorithm is overly confident or lacking in determining an incorrect decision. If the accuracy rate is low, the machine goes through an active learning cycle wherein humans give feedback for the machine to reach the correct result or increase its predictability.
Real World Applications of Human-in-the-Loop Machine Learning
Social Media
For social networking platforms to be a safe space for everyone, large scale content moderation services are needed. AI optimizes content moderation services to recognize patterns and automatically detect and censor sensitive content. Humans first train the system to identify text, usernames, images, and videos for hate speech, cyberbullying, explicit or harmful content, fake news, and spam. The data then goes through finetuning and eventually testing to check contextual and language nuances.
HealthTech
A medical imaging model can powerfully and accurately detect malignant and benign cells before recommending treatment. To keep machines up to speed, subject matter expertise, up-to-date training, and familiarity are key. High-quality medical datasets are difficult to find because of limited healthcare data and patient data protection laws. Thus, HealthTech companies rely on data labelling services to augment their training data.
Transportation
To develop self-driving cars, massive amounts of image, video, or sensor data are collected and annotated by humans. For the self-driving car to correctly recognize objects in its environment, it requires adequately labelled examples to identify pedestrians, bikes, trees, and more. These details provide insight to various malperforming scenarios.
Benefits of Human-in-the-Loop Machine Learning
Augment Rare Training Data
While there are many open source datasets available on the web, they generally don’t work for specific problems. For such rare use cases, the data needs to be created and curated by humans.
Increase Safety & Precision
There are many instances where you need human-level precision to ensure safety and accuracy. For example, when developing a fleet of autonomous vehicles, it is best to have the system monitored by humans to catch and fix any failure cases.
Incorporate Subject Matter Experts
By having a team of subject matter experts (SMEs) collecting and annotating training data, you can create some very sophisticated applications. For example, a medical image analysis algorithm would require a wealth of meticulously annotated image data by experts in the field.
Human-in-the-Loop Data Labeling with Us
Artificial intelligence is only as intelligent as the data it’s given. Machine learning still requires highly capable data annotation experts to ensure an excellent performance model. It’s just a matter of finding the right balance between people and technology.
TaskUs sets itself apart with its people-first culture in the fast-paced, tech-dominated industry. We provide data collection, annotation, and evaluation services to power the most innovative AI solutions. Whether you’re building computer vision or natural language processing (NLP) applications, we are equipped to handle complex, large scale data labelling projects.
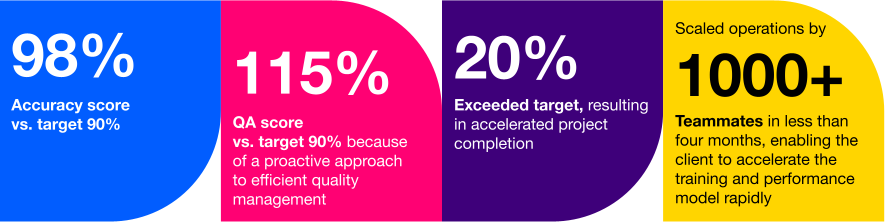
One of our clients include a leading autonomous vehicle company wherein we provide optimized data annotation and labeling services to help them achieve rapid scaling of their operations. Our expert AI Operations solutions resulted to:
Partner with Us in building better-performing machine learning models faster and more efficiently.
