
Did you know that 68% of shoppers would not return to a site that provided a poor search experience?
Not only that, people who use site search on e-commerce sites are more likely to purchase products, with a conversion rate of 50% higher than average2. Today, anyone can search anything on Google and expect relevant results based on location and preferences within milliseconds!
Once the customer enters a keyword such as “dove,” the search engine will crawl through a plethora of internet information. But how does it know if the desired result for the query is a soap, a chocolate bar, or a bird?
This is why fine-tuning search relevance is crucial for your business.
What Is Search Relevance?
Search relevance is a measurement of how closely related a returned result is to its query. When search results match user intent, you’ve achieved relevance. Good search algorithms understand the context of the user’s queries and deliver relevant results.
So how can you optimize search relevance?
The process starts with collecting ground truth data that the search algorithm can learn from to make correct decisions. This training data is used to train algorithms on contextual information such as natural language text and user intent.
Training data created from search query categorization teaches algorithms the indicators that help distinguish between related queries. Learning all possible iterations of this is the challenge companies face without proper training through data labeling of their datasets.
The accuracy of training data directly determines the accuracy of the trained model. Thus, it is critical to put great effort and investment into the collection and annotation of high-quality data.
That’s where human intervention comes into play.
Why Human-Annotated Data is Key to Search Relevance?
Natural Language Processing (NLP) is the branch of artificial intelligence that helps search engines understand and respond to user queries. In order for NLP-based search algorithms to improve, they need to be trained with large sets of natural language data enhanced with metadata on user intent, named entities, sentiment, and more.
As such, it’s most beneficial to implement a human-in-the-loop approach to building and refining AI-based search systems. In this workflow, human evaluators rate whether specific inquiries are providing relevant search results. Human evaluators judge search results, giving critical feedback and new training data to the algorithm. A diverse base of evaluators (demographically, linguistically, among others.) helps the algorithm perform better across markets.
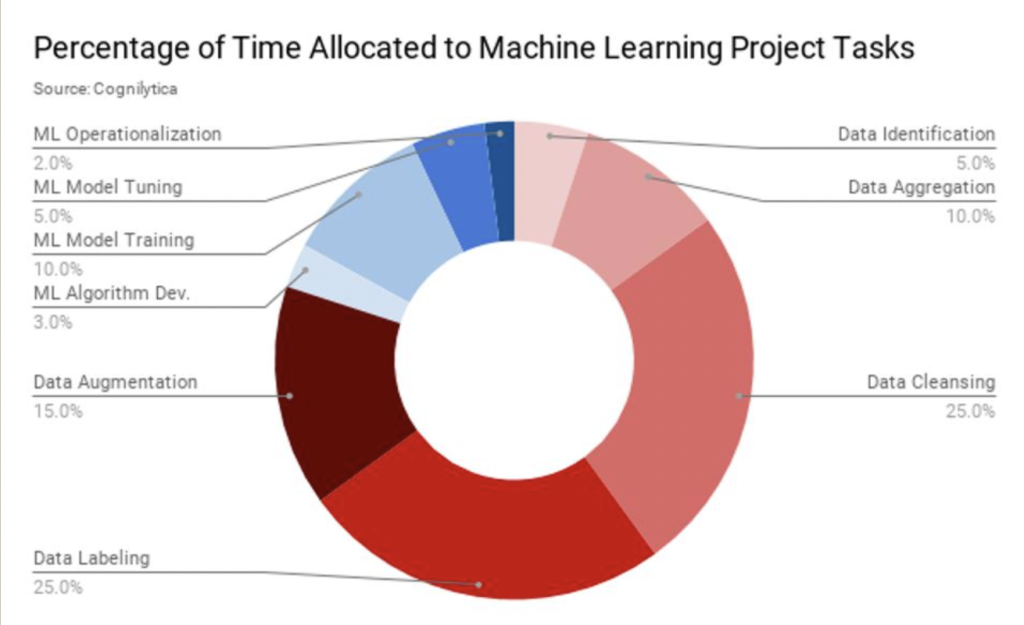
As a result, the majority of time allocated in machine learning projects is dedicated to data collection and annotation. Based on a report by analytics firm Cognilytica, ¼ of total developer time is spent on acquiring labeled data. Some companies have plenty of raw data but lack the resources to support large-scale data labeling or lack an effective process to ensure accuracy and quality4.
Types of Search Evaluation Services
There are several types of services that data labeling companies offer to improve search relevance. The most popular is the evaluation of search results, wherein evaluators determine whether or not a particular search result is relevant to a search query.
In the past, relevance was based on the frequency of the appearance of keywords on a webpage. Now instead, search relevance puts greater emphasis on accuracy and context. Search result evaluation can be done through the following:


The evaluator’s assessment of the search results is then used as an input for the search engine’s algorithm, bringing in more accurate results on top of the list.
Another type is ads evaluation. Like search result evaluation, evaluators are tasked to assess the relevance of advertisements based on what users are searching. Ads are known to have an impact on customer search experience; which is why evaluators also cross-check the appearance of the ads with the corresponding landing page.
Other types of search evaluation tasks such as auto-fill evaluation and recommendation evaluation—where related results are predicted and suggested by the search engine based on the search query—are also geared towards improving search experience.
Best Practices for Data Labeling
Organizations must adopt the most optimal data labeling practices to minimize the labeling cost and time. This significant step will result in an efficient data labeling process and develop accurate datasets to train high-quality models.
Here are some of the best practices for data labeling that we recommend:
Evaluator training
Given that data annotators must work on repetitive and time-consuming tasks, in-house teams struggle to allocate sufficient staff and meet the high demands. Additionally, the lack of domain knowledge will only lead to inaccurate models. Thus, human evaluators should be carefully pre-screened and qualified, and should work within strict guidelines to ensure high-quality training data.
Project design
Data labeling projects can be overly complicated and costly, which is why it’s essential to design workflows to capture high-quality, diverse training data. Without explicit goals and careful planning, your data pipeline can easily become messy.
Data problems trickle down to model development, potentially causing issues in the model’s ability to make predictions. To ensure you only collect meaningful data, it’s necessary to break down complex labeling projects into a series of simple tasks with crystal clear instructions for labelers.
In addition, the data collected should be diverse, capturing all user demographics, languages, geographic locations, and more. Ensuring the quality and diversity of data is an integral part of the project design in AI data operations. Failure to spot and anticipate issues in the training data will lead to operational inefficiencies, financial and legal repercussions, and even public scrutiny. Apart from analyzing the integrity of the data, it’s also crucial to revisit and analyze the first trained model. More often than not, the first model formed is suboptimal, and finding the right design and the right combination of parameters and tools can provide additional precision.
Choose the right partner
If a company is to outsource its AI development, one must vet every effort to find the most qualified partner for the task at hand and be convinced you can rely on the people you end up working with. Here are some of the most vital points worth considering:
- Quality
The importance of quality data cannot be stressed enough. Quality data is the bedrock for building advanced Artificial Intelligence and Machine Learning. While the tools and security protocols of outsourcers are constantly changing, the quality of data being produced should be an obsession in achieving businesses’ AI development goals. With custom-built teams, gold standard processes, proactive monitoring, feedback loops, and other quality control measures, you can count on getting the most value from your training data. - Experience
Every trustworthy outsourcing partner will have a solid track record of past projects. When vetting an outsourcer’s portfolio, pay particular attention to projects that relate to your specific industry. In addition, check if the processes delivered tangible results, or other projects sparked innovative ideas that inspired the team to seize more opportunities. - Organizational Culture
Organizational culture is the inclination of values, behaviors, and experiences that contribute to the company’s social standards, safety environment, and business practices.
Culture is not a factor that should be taken lightly; it can be a great indicator of a partner who is the right fit for you. Be on the lookout for outsourcing that looks after their employee experiences, like those who offer best-in-class benefits such as paid maternity, scholarship programs to employees’ children, and exceptional health coverage. However, culture is not just about these benefits; it is about how an organization pulls together to advance or push a vision and produce incredible results while caring for its people.
Ensuring the quality and diversity of data is an integral part of the project design in AI data operations.
Optimize Your Search Relevance with TaskUs
Quality training data is the foundation of any successful AI model. With 10+ years of experience in delivering data labeling services, TaskUs has the human capital and process expertise to build that very foundation.
Data quality is our main obsession and this permeates throughout the whole Search Evaluation process. Combined with best-in-class labeling tools and industry standard security protocols–optimal and accurate search relevance for your business is just a call away.
Learn more about our data labeling services. Get in touch with our team today.
